三、SQL语句
8.2 SQL语言主要类型
sql语言最常用的功能:
查询及修改数据
创建数据库对象
权限管理
这三类语言分别称为:DML,DDL和DCL。
主要的SQL语句和功能:

SQL语言主要分为:DDL语句,DML语句,事务控制语句,会话控制语句,系统控制语句,嵌入式SQL语句。
8.3 常用的数据类型与解释
Oracle常用的数据类型:数值、字符串、日期时间。
8.3.1 数值类型
数值类型为number[(p,s)],主要用来存储0、正负定点数、正负浮点数。
参数p与s:p代表有效数字,s代表精度,即小数位数。范围p(1到38),s(-84到127)。
省略S就代表不包含小数的整数。S>0,代表精确到小数点右边s位,并且四舍五入。S<0与之相反。
8.3.2 字符串类型数据
字符串四种类型:
char(n),varchar(n),nchar(n),nvarchar(n)。
char(n):用于存储固定长度的字符串,n最大2000字节。如果添加的字符串小于n,则用空格补齐。
varchar(n):存储可变长度的字符串,参数n不能省略。
char(n),varchar(n)与nchar(n),nvarchar(n) 区别在于前者使用UTF编码后者使用国家字符集。
8.3.3 日期时间数据类型
date类型数据固定使用7个字节存储空间,包括年月日小时分钟秒,精确到1秒。
初始化参数由nls_date_format决定。
8.4SQL语句示例
8.4.1 select命令
一般来说select语句主要有:
select ... from ... where ...
构成。其中select子句指定查询的列名,from子句指定要查询的表名,where子句指定查询条件。举例:
select * from dept; //查询dept表所有的数据
select ename,sal from emp; //查询emp中ename和sal列的数据
select ename "EMPLOYEE NAME",sal salary from emp; //ename和sal使用别名EMPLOYEE NAME 和salary。
//注意上句中使用别名EMPLOYEE NAME时含有空格,需要使用双引号"EMPLOYEE NAME"加以限制。
select ename as "EMPLOYEE NAME" from emp; //使用as关键字8.4.2查询条件
先熟悉关系运算符和逻辑运算符,这些主要用于where子句指定条件。
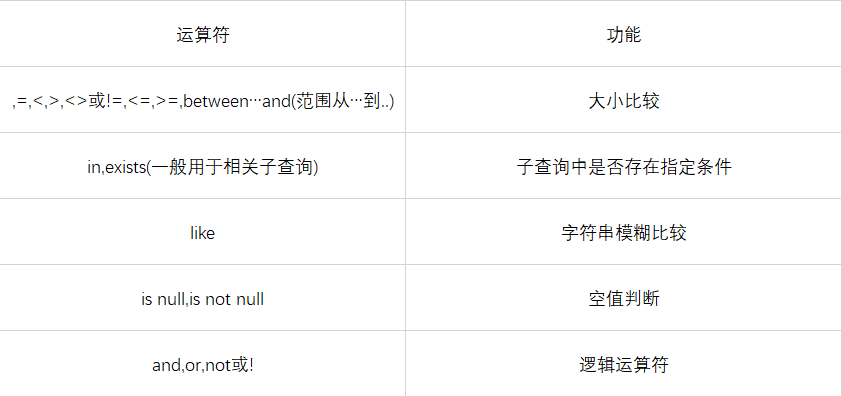
使用上图中符号进行查询:
select ename,sal from emp
where deptno = 10 and sal between 2000 and 3000;
//查询emp表中10号部门中工资(sal)在2000到3000之间的员工的名称和工资。使用order by子句查询:
select ename,sal
from emp
where deptho = 20
order by sal asc;
//查询20号部门中的员工名称和工资,并且按工资从低到高排序。
//后接参数asc表示从低到高,desc表示从高到低排序。order by指定多个列排序:
select deptno,ename,sal
from emp
order by deptno,sal;
//指定多个列排序,此时排序按照deptno排序再按Sal排序。
补充:后文出现的distinct也是排序的作用 这个关键字来过滤掉多余的重复记录只保留一条 ,然后进行排序从高到低。
8.5 常用数值,字符,日期处理函数
8.5.1 常用数字处理
- abs()求绝对值
- mod()取模
- sqrt()求平方根
8.5.2 字符串数据处理
1:字符串模糊查询与查询特殊字符
- 使用%或_作为模糊匹配
- %:表示任意个任意字符
- _:表示一个任意字符
- 代码中关键命令为like
select ename from emp
where ename like 'S%';
//查询emp表中以S开头的员工名称。
select dname from dept
where dname like '%\%%'
escape '\'; //定义转义字符为\
//查询dname中含有%的名称2:常用的字符串函数:
- ||:合并字符串
- concat():字符串合并,其中需要两个字符参数。
- length():求字符串长度,需要一个参数。
- lower()/upper():把字符串转化为小写/大写,需要一个字符参数。
- lpad()/rpad():在字符串的左/右侧附加指定字符,需要三个参数。
- replace():用一个子串代替字符串中的指定部分,三个参数。
- substr():获取子串,截取原有字符串中部分子串,需要三个参数。
- trim():去除字符串两端的空格或指定字符,需要一个参数
代码演示:||,lpad,replace
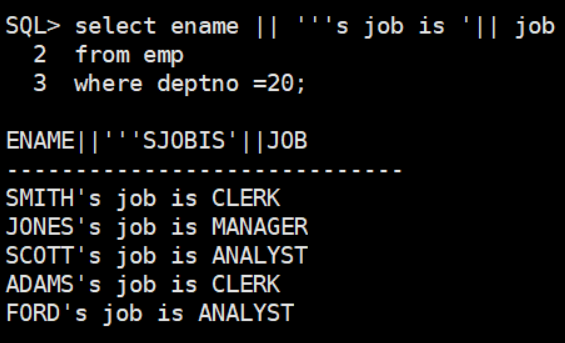
||拼接字符串 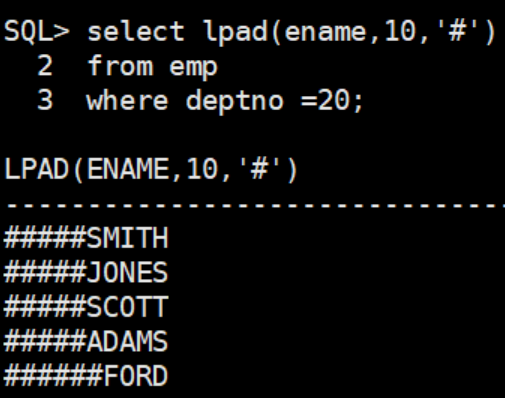
作用在字符串左侧添加#号直到长度为10
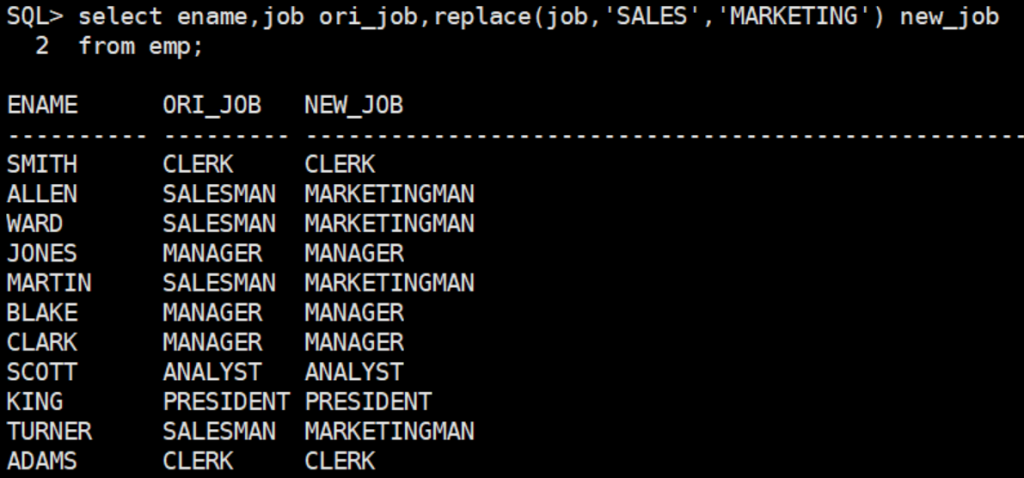
上面replace函数三个参数分别是:选择字符串常量,原有字符串中的字符,替换后的新字符。
3:常用的日期处理函数:
获取当前日期时间:select sysdate from dual;
to_char()函数:把日期类型转化为指定格式字符串。
to_date()函数:包含两个参数,第一个表示日期的字符串常量,第二个是格式码。
select ename from emp
where hiredate = to_date('1981-02-20','yyyy-mm-dd');
//查询ename列中日期满足1981-02-20的人的名字extract()函数:抽取日期中的指定部分。
select ename from emp
where extract(year/month/day/hour/minute/second/ from hiredate) = 1980;
//查询emp表中所有1980年的员工名称,年也可以换成其他时间参数。获取时间差的办法:1,date'1980-02-20' - date'1980-02-18' ; 2,round()函数。round()函数解析,先define两个时间参数:
define startdate = "to_date('2013-08-10 15:30:25','yyyy-mm-dd hh24:mi:ss')";
define enddate = "to_date('2013-09-15 12:30:25','yyyy-mm-dd hh24:mi:ss')";
解释:define关键字,用来定义了两个date参数的值,其中hh24代表24小时制,在引用date参数时,需要使用&enddate这种形式。
- 相差天数:round(&enddate-&startdate)
- 相差小时数: round(round(&enddate-&startdate)*24)
- 相差分钟数:round( roud(&enddate-&startdate) *24*60)
- 相差秒数: round( roud(&enddate-&startdate) *24*60*60)
针对两个define定义的时间差指计算代码:
select round((&enddate-&startdate)*24) as hours from dual;
//计算了两个date之间的差了多少天并且用替代名hours显示。4:空值的处理:
Oracle遇到null值的判定的时候只能使用is null和is not null判断,不能使用=与<等判定。代码示例:
select ename from emp
where comm is null;
//查询emp表中,comm列为空的员工名称。5:分组汇总查询:
汇总函数也称为分组函数,主要用户查询指定列的最大值、最小值、平均值、总和及非空列值数,函数分别称为max、min、avg、sum、及count。代码示例:
select max(sal) from emp; //查询emp表中sal列的最大值
select min(sal) from emp; //查询emp表中sal列的最小值
select avg(sal) from emp; //查询emp表中sal列的平均值
select sum(sal) from emp; //查询emp表中sal列的总和
select count(comm) from emp; //查询emp表中comm列的非空值个数注意!使用分组函数一定要与group by一起使用!!
8.6其他子句的使用
8.6.1group by子句使用
group by按照指定列的不同值分组后,再查询其他指定列的汇总值。代码示例:
select deptno,sum(sal) from emp
group by deptno;
//查询emp表中每个部门的sal总和,以deptno列分组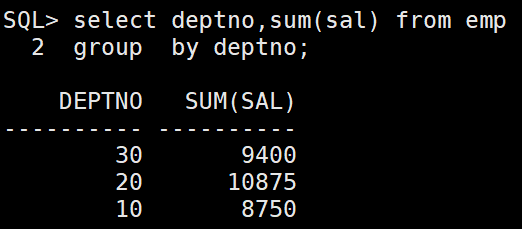
在select子句中出现,并且未被分组函数作用的列都要在group by子句中出现,否则会报错!!
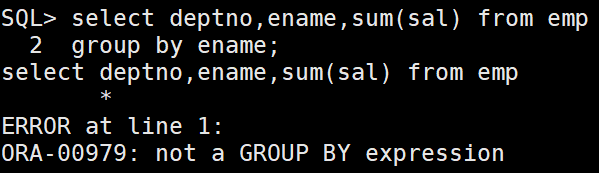
8.6.2 having子句
where子句在分组前对记录进行过滤,如果要对分组之后的结果过滤,则可以使用having子句附加条件。代码示例:
select deptno,sum(sal) from emp
group by deptno
having sum(sal)>7000;
//查询emp表中sal总和超过7000的deptno(部门编号)和工资总额。⭐如果having子句中的列不含分组函数,则此列要预先在group by子句中出现。(同时注意前面select和group by子句的使用注意)
8.6.3 in与not in
用于判断一个子查询结果中是否出现了某个表的列值,可以看作元素与集合的关系。代码示例:
select dname from dept
where deptno not in
(select distinct deptno from emp); //distinct函数,排序从高到低,排除重复的选项
//查询dname名称从dept表中,要求dname满足其对应的deptno不在emp的deptno列值中。not in与in不能用来检测子查询结果中含有null值,需要提前对子查询结果排除null值否则会出现意外情况。具体示例参照课本P94。
8.6.4 exists与not exists
它们的作用与in和not in相似,但是exists更有存在的含义,这两个子句一般使用相关子查询。代码示例:
select dname from dept
where exists(select deptno from emp where deptno = dept.deptno);
//where deptno = dept.deptno第一个deptno是emp表中的,第二个是dept表中的。结果限定deptno满足两表的deptno相等。
//这段语句作用:使用exists查询有员工的部门名称。not exists与exists能用来检测子查询结果中含有null值!
8.6.5使用表别名
使用表别名引用各自的列,有更好的可读性。代码示例:
select e.ename,e.deptno,d.*
from emp e,dept d //表别名使用
where e.deptno = d.deptno;
//emp与dept分别使用别名e和d,然后查询ename,deptno,dept表中满足emp与dept表deptno相等的信息。8.7 数据修改语句
8.7.1 delete语句
delete用于删除表中的记录(与truncate区分),一般会附加where子句限定删除记录的范围,不附加where则删除整个表的数据。代码示例:
delete from emp; //清除emp表中的数据
delete from emp where deptno = 10; //删除emp表中deptno=10的部门记录8.7.2 update语句
update用于修改表中记录的列值,一般会附加where子句。代码示例:
update emp set sal = 2000,comm = 1200 where deptno = 20;
//修改emp的deptno的20部门中的sal与comm列值。8.7.3 insert语句
insert语句用于向表中添加记录,也就是添加行值。代码示例:
//第一种方式
insert into dept(deptno,dname)
values(50,'HR');
//对dept表增加一行记录,对deptno与dname增加一行50,HR值,第三个列未出现则为null。
//第二种方式
insert into dept values(60.'RD',null);
//对dept增加一行值对应的列值分别为60,RD,null8.7.4构造复杂的update语句,代码示例:
//把emp表中工资超过其经理的员工工资降低1000
update emp set sal=sal-1000 //更新sal值,在原有基础减去1000
where empno in //要求更改的sal对应的empno满足在下面的员工列中
(
select e.empno //找出empno,e和m为emp表别名
from emp e,emp m //从emp表中找出
where e.mgr = m.empno //where子句要求满足mgr等于empno并且同时满足员工sal大于经理sal
and e.sal > m.sal
);8.8创建表,约束,添加与修改列
8.8.1 创建表代码示例:
create table t(a int,b char(15))
tablesapce tbs;
//创建一个表t其中含有两列分别是int a和15字符长度的b
//指定表空间为tbs8.8.2对列或者表添加约束
约束种类:
- 主键约束:列值不能为空也不能重复
- 唯一约束:列上的值不能重复
- 外键约束:列值要匹配与其指向主表的相应列值
- 检查约束:给列的取值范围附加限制
- 非空约束:列上的值不能为空。只能附加在列级
- 默认约束:如果某些列未赋值,取默认约束中所指定的值。
表的约束主要分为:列级约束与表级约束。代码示例:
create table t
( a int primary key, //列级约束,未指定约束名称
b int constraint pk_test primary key //列级约束指定名称
//constraint <约束名> primary key(主键含义)
);
create table t1
( a int,
b int,
primary key(a) //表级约束,未指定名称
//constraint pk_test primary key(a) 表级约束指定列名称
//constraint <约束名> primary key(主键含义) <>列名
);8.8.3 修改表的结构
//修改列数据类型
alter table dept modify dname vatchar2(20);
//修改dept表中dname的数据类型未varchar(20)
alter table dept modify (dname vatchar2(20),loc varchar2(20)); //修改多个
//添加及删除列
//添加列:alter table 表名 add 列名 数据类型
//删除列:alter table 表名 drop column 列名
alter table dept add phone_number char(12); //对dept表添加列phone数据类型char(12)
alter table dept drop column phone_number; //删除dept中的phone列
//修改列名
//形式:alter table 表名 rename column 旧列名 to 新列名
alter table dept rename column loc to location
//修改表名
//形式:alter table 表名 rename to 新表名
alter table dept rename to dept1;
//清空表:truncate table 表名
truncate table emp; //清空emp表
//删除表
drop table emp; //删除emp表truncate与delete相比,首先执行后不能使用rollback撤回因为它是ddl语句,其次它是通过释放表占用的空间删除数据。
Comments NOTHING